
In SEO (Search Engine Optimization), Latent Dirichlet Allocation (LDA) can help improve content by better understanding the relationship between keywords and topics. Here’s how LDA relates to SEO and why it’s useful:

1. Content Relevance and Topic Modeling:
Search engines like Google aim to understand the meaning and relevance of a webpage, not just count the number of keywords. LDA can help identify topics that naturally occur in content, allowing you to understand the broader themes that your page covers. This means you should focus on creating content that covers related topics naturally rather than stuffing a single keyword.
For example, if you’re writing about “healthy eating,” LDA might suggest that words like “nutrition,” “diet,” “exercise,” and “calories” are also relevant to this topic. Incorporating these words will make your content more complete and aligned with what users expect to see.
2. Semantic SEO:
LDA encourages semantic SEO, which focuses on optimizing content for the meaning behind the search query rather than just focusing on exact keywords. Search engines are now smart enough to understand related terms and topics, so using LDA can help create content that provides deeper insights and answers related to the main topic.
For instance, if you’re targeting the keyword “digital marketing strategies,” LDA might show that the topic should also include related concepts like “social media,” “SEO,” “content marketing,” and “email campaigns.” Covering these will make your page more comprehensive.
3. Natural Language Processing (NLP) and LDA:
Google uses advanced NLP algorithms to understand the context of content. LDA, by breaking down content into topics, can align your content with how Google interprets meaning. It allows Google to determine if your page answers a user’s query in a meaningful way based on its topic coverage.
When Google crawls your website, LDA-like processes help it understand the latent topics on your page. If your content covers a variety of related subtopics that naturally fit together, Google is more likely to rank your content higher because it believes you’ve provided a comprehensive answer.
4. Keyword Clustering:
Instead of focusing on a single keyword, LDA helps you understand clusters of related keywords. This approach aligns with how search engines rank pages based on topical depth. For example, for a page targeting “home workouts,” an LDA analysis might suggest related terms like “bodyweight exercises,” “workout routines,” “fitness goals,” and “cardio.” By including a range of related terms, you’re more likely to rank for different variations of search queries.
5. Improving Content Structure:
LDA can also help structure your content more effectively. By identifying the different topics in your content, you can organize sections better. For example, if you’re writing a blog post about “healthy recipes,” LDA might suggest breaking it down into subtopics like “breakfast recipes,” “dinner recipes,” “snacks,” and “ingredients to avoid.” This makes your content easier to navigate and improves its overall relevance.
6. Avoiding Keyword Stuffing:
With LDA, you don’t have to repeat a keyword excessively to signal relevance. Instead, focusing on naturally using a variety of terms related to your main topic will improve SEO. By covering all the relevant topics within a single piece, your page will appear more authoritative and rank better.
Example of LDA in Action for SEO:
Let’s say you’re optimizing a page for “best hiking shoes.” Traditionally, you’d use the exact keyword “best hiking shoes” multiple times. But with an LDA approach, you would also consider including terms like:
- “outdoor gear”
- “trail running”
- “foot support”
- “breathable materials”
- “hiking tips”
This makes your page more contextually rich, and search engines will recognize that your page offers more depth on the subject.
Summary of Benefits for SEO:
- Improved topical relevance: LDA helps identify the topics related to your main keyword, so you cover a broader range of related content.
- Better keyword clustering: You rank for multiple terms that are related to your topic rather than just one.
- Boosted user engagement: Well-structured content based on LDA keeps users on your site longer because it provides complete information.
- Higher rankings: Pages optimized with LDA are seen as more relevant by search engines, increasing their chances of ranking higher.
LDA is a generative probabilistic model. This means it assumes that each document in a set of documents was created by a process that involves some hidden topics. The goal of LDA is to uncover these hidden topics and figure out which words are associated with which topics, and how each document is a mix of those topics.
Key Concepts:
- Documents: Each document is made up of words. Think of a document as a bag of words, where we don’t care about word order, just the words themselves.
- Topics: Topics are hidden (latent), and each topic is essentially a collection of words. For example, a topic about sports might contain words like “team,” “game,” “ball,” “score.”
- Dirichlet Distribution: LDA uses something called a Dirichlet distribution to model:
- The distribution of topics in each document.
- The distribution of words in each topic.
How LDA Works:
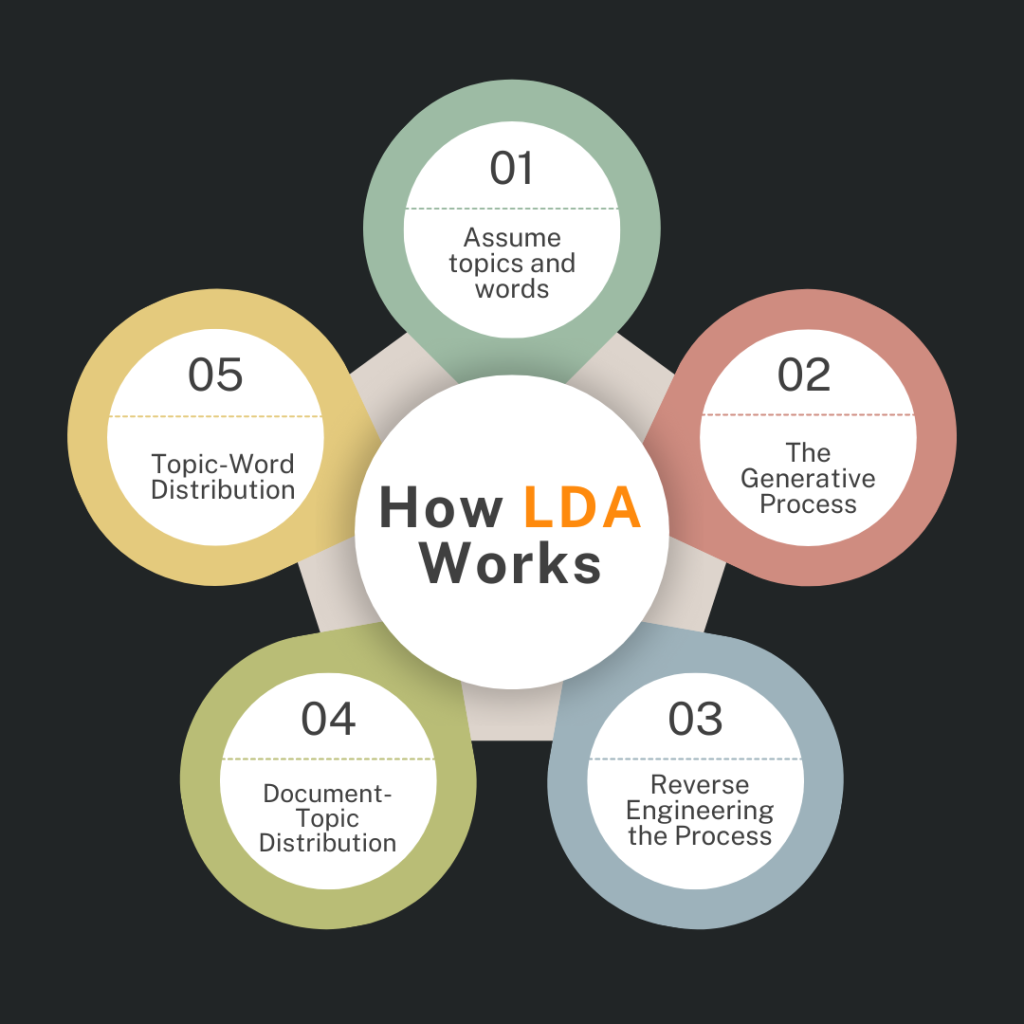
- Assume topics and words: LDA assumes that:
- Each document is a mixture of a small number of topics.
- Each topic is a mixture of words.
- The Generative Process: The generative process describes how LDA imagines each document was created:
- For each document, LDA randomly picks a set of topics from the Dirichlet distribution. The distribution ensures that each document might focus more on some topics and less on others.
- For each word in the document, LDA selects a topic according to the topic distribution for that document.
- It then picks a word from that topic’s word distribution.
- Reverse Engineering the Process: LDA’s task is to reverse engineer the process. Given a bunch of documents, it needs to figure out:
- What topics are hidden in the data.
- Which words belong to which topics.
- How much of each topic is present in each document.
In More Detail:
- Document-Topic Distribution: For each document, LDA assumes there’s a mixture of topics. For example, Document A might be 70% about “sports” and 30% about “health.” This is represented as a probability distribution for the document.
- Topic-Word Distribution: For each topic, there’s a probability distribution of words. For example, the topic “sports” might have a high probability of words like “team,” “score,” and “game.” The topic “health” might have a higher probability of words like “doctor,” “medicine,” and “exercise.”
- LDA’s Task: LDA tries to find the best possible assignment of topics to words and documents so that it explains the data in the most probable way.
Example:
Let’s say we have three documents:
- Document 1: “lions tigers forests trees”
- Document 2: “planets stars galaxies space”
- Document 3: “rockets astronauts planets tigers”
- LDA might find that there are two topics:
- Topic 1 (Animals): “lions, tigers, forests”
- Topic 2 (Space): “planets, stars, rockets”
- It might say:
- Document 1 is 100% Topic 1 (Animals).
- Document 2 is 100% Topic 2 (Space).
- Document 3 is 50% Topic 1 (Animals) and 50% Topic 2 (Space).
In Summary:
- LDA takes a set of documents and tries to figure out the hidden topics that make up those documents.
- It assumes each document is a mix of topics, and each topic is a mix of words.
- It uses probability distributions to model the relationship between documents, topics, and words, and iterates to find the best possible structure of topics.
The magic of LDA lies in how it can uncover these hidden topics just by looking at the words in the documents without knowing anything about the actual content beforehand!
In SEO, using LDA principles means focusing on comprehensive, topic-rich content that naturally incorporates related terms and concepts to provide users with valuable, well-rounded information. This helps improve your search rankings and enhance the overall quality of your content.